The gaps in Europe’s Frontier AI Strategy
Perspectives from our application to the EU’s expert forum on Frontier AI
When the European Commission’s AI Office invited applications for its inaugural Expert Forum on Frontier AI, we expected the conversation to centre on a familiar question: how does Europe build its own foundation models to compete with the US and China?
We think that question matters – but it’s incomplete. Europe absolutely needs the strategic capability to train frontier models. But the gap between a powerful model and one that’s actually useful for European science and industry is where most of the value is created, and where Europe is most visibly falling behind. No one questions a researcher for using established statistical methods rather than reinventing regression from scratch. The value lies in applying the right method to the right problem, in understanding the assumptions, the failure modes, the domain-specific adaptations that make a general tool scientifically useful. Yet in AI research funding, if you haven’t trained a new model, the work is often dismissed as insufficiently novel – even when the adaptation itself is the hard, unsolved problem. The European AI strategy should focus on solving the greatest challenges we face in an efficient and safe way.
The Expert Forum meets on 23 April 2026 to develop strategic recommendations for EU competitiveness, sovereignty, and security in frontier AI. Our response to the Forum focused on three areas: the structural gap in how Europe funds and supports AI research, why scientific and industrial AI demands a fundamentally different approach to evaluation and reliability, and a proposal for rethinking AI security as shared infrastructure rather than per-model restriction.
The Adaptation Gap
Here’s a pattern we’ve seen repeatedly in Horizon Europe project evaluations: a consortium proposes to train a new model from scratch. The reviewers approve it. Eighteen months later, the model is finished — and already outperformed by three open-source releases that appeared in the interim. The compute, the energy, the researcher-years: all spent re-deriving capabilities that were freely available.
The alternative – taking a frontier open model and systematically adapting it for a specific scientific domain – scores poorly on novelty. “Where is the architectural innovation?” ask the reviewers. The innovation is in making it work. In injecting domain knowledge without catastrophic forgetting. In aligning embedding spaces with terminology that doesn’t exist in any pre-training corpus. In extending a model’s vocabulary to handle modalities it was never designed for. This is difficult, unglamorous, essential research – and Europe systematically underfunds it.
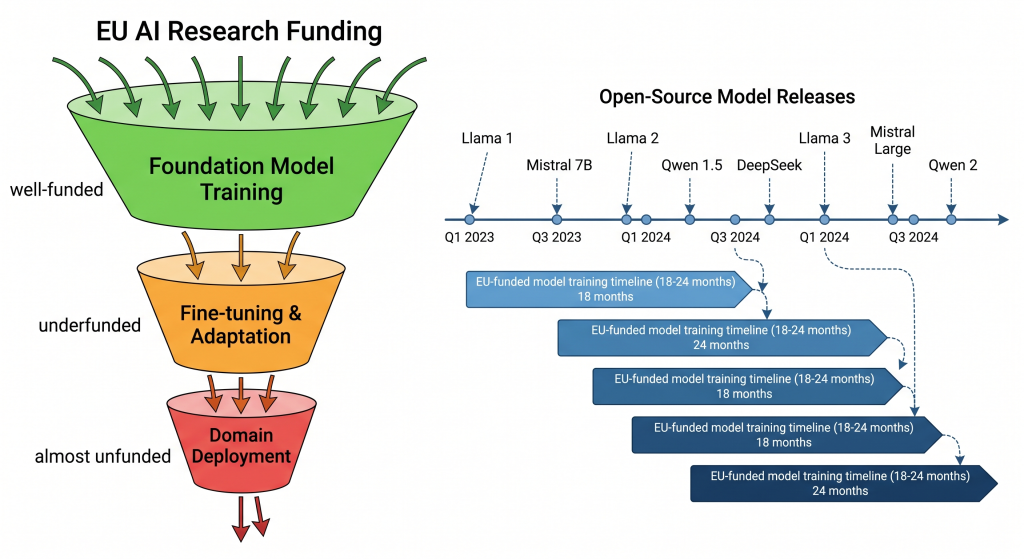
The result is a structural paradox: Europe funds the most expensive path to capabilities that arrive free, while neglecting the cheaper path to capabilities that don’t yet exist.
The cost of compliance
Part of the solution lies in reducing the need for retraining altogether. Scientific knowledge evolves faster than any model can be updated, but effective external memory systems – retrieval-augmented generation, structured knowledge graphs, adaptation repositories – can keep deployed models current without expensive retraining cycles. European infrastructure such as EOSC could serve as a backbone for making research data AI-accessible, but integration between AI systems and EU scientific data infrastructure remains underdeveloped. The hardware and long-term funding needs for AI integration in EOSC may be systematically underestimated.
This creates downstream consequences beyond wasted resources. The AI Act creates compliance obligations that don’t neatly map onto the open-source adaptation pipeline. When a European SME takes an open foundation model and fine-tunes it for a high-risk industrial application, that company can become a “provider” under the AI Act – inheriting full conformity assessment obligations for a system whose base model they didn’t train and whose training data they cannot fully audit. The obvious response is: use a compliant European base model. But this forces a choice between regulatory convenience and technical capability. Today’s most capable open frontier models are overwhelmingly non-European, and European alternatives – while improving – do not yet match them across all domains. An SME choosing a less capable base model for compliance reasons may deliver a less competitive product than a US counterpart building on the same frontier model without equivalent regulatory overhead. The answer is not to weaken compliance, but to invest in the infrastructure that makes compliance feasible regardless of which base model is used – systematic evaluation tooling, shared conformity assessment frameworks, and the kind of decoupled security architecture we propose later in this blog post.
Meanwhile, the compute access model compounds the problem. In the US, startups routinely receive cloud research credits from hyperscalers – a low-friction path to sustained GPU access that has no European equivalent. Within Europe itself, the picture is uneven: universities often bridge the gap through access to national or regional HPC clusters, but SMEs are excluded from these arrangements. A Belgian AI company pays market rate for the same GPU hours that a Belgian university accesses for free and an American startup gets through a credits programme. The playing field isn’t just uneven internationally – it’s uneven within our own ecosystem.
Europe’s AI Factories and Gigafactories are serious investments, but their allocation mechanisms favour the training paradigm. Getting approved for a massive compute run on a supercomputer for three months? Possible. Getting moderate but sustained GPU access for six months of iterative experimentation – the kind of work adaptation actually requires? That falls into a gap: too large for cloud budgets, too small and too irregular for HPC allocation committees. The infrastructure exists. The access model doesn’t match the work.
Why Scientific AI Plays by Different Rules
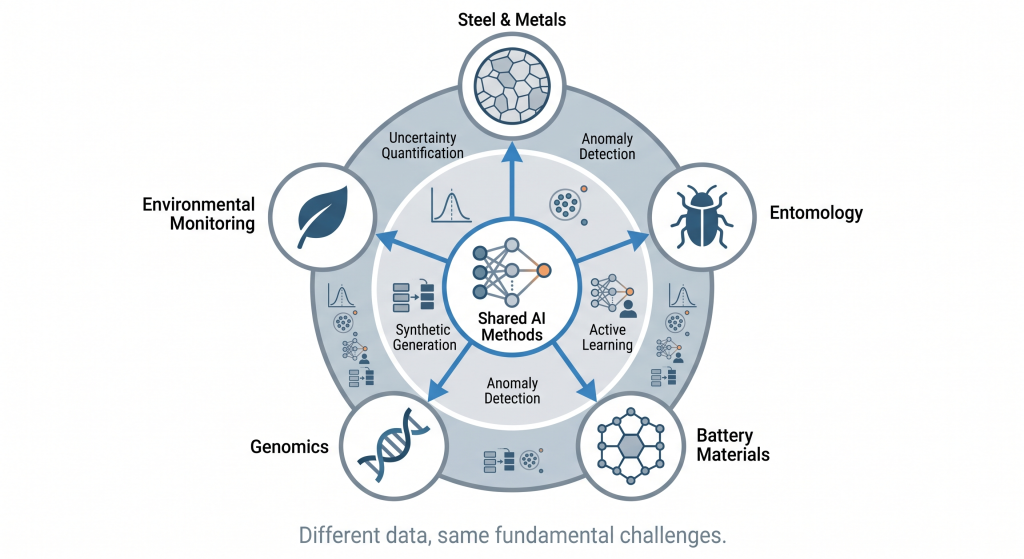
Our own work spans from materials to life sciences, ranging from steel, to batteries to detecting viruses or counting insects. These domains look nothing alike until you realise the AI challenges are nearly identical: scarce labelled data, complex multi-modal measurements, and a fundamental need to know when the model is out of its depth.
That last point deserves emphasis. A model that’s confidently wrong about a steel microstructure can send a production batch to scrap. A model that’s confidently wrong about a battery material can waste months of synthesis effort. A model that hallucinates a genomic variant can derail a diagnostic pathway. In scientific AI, calibrated uncertainty – knowing what you don’t know – is more valuable than accuracy on the cases you do know.
This is a fundamentally different design philosophy from consumer AI, where confidence is a feature. It requires different evaluation frameworks and different benchmarks. And here lies another gap: we don’t have good ones. Public AI benchmarks reward optimisation along narrow general-capability axes – language understanding, code generation, reasoning puzzles. Large-scale, evolving benchmarks for scientific and industrial domains are largely absent.
Where benchmarks do exist for scientific domains, they tend to use curated academic datasets that don’t reflect the noise, class imbalance, and distribution shift of real industrial deployment. A model scoring 95% on a clean test set may fail unpredictably on production data from a different microscope, a different insect trap design, a different steel grade. Domain-specific benchmarks should be co-developed with scientific communities and practitioners, built from real-world data distributions, regularly refreshed to prevent the saturation that plagues general AI benchmarks, and potentially linked to existing research repositories such as Zenodo.
Without such benchmarks, we cannot compare approaches, assess real-world impact, or justify continued investment. We cannot even properly articulate what “frontier” means for scientific AI – a question the Forum might usefully address.
What about security?
The AI Act classifies risk partly based on training compute – a reasonable starting point, but one that’s already fraying. Compression, distillation, and quantisation are demolishing the link between model size and capability. A 7-billion parameter model today can match what required 70 billion parameters two years ago.
For social manipulation, the threat isn’t a superintelligent AI. It’s a million cheap ones. A propaganda network doesn’t need deep knowledge or sophisticated reasoning. It needs passable text generation, a consistent persona, and massive scale – potentially running on compromised consumer hardware. A significant proportion of LLM parameters encode factual knowledge – essentially compressing internet-scale text — rather than reasoning or linguistic capability. Manipulation requires primarily linguistic fluency and goal-directed behaviour, achievable at much smaller scales, or through a capable model orchestrating a swarm of lightweight agents. This threat scales with cost-efficiency, not with FLOP counts, and falls almost entirely outside current regulatory thresholds.
For scientific and industrial domains, the picture inverts. Restricting what models know about chemistry, biology, or nuclear physics sounds protective until you consider what dangerous queries actually look like. They don’t look like “How do I synthesise a nerve agent?” Rather, they tackle the day-to-day challenges a real scientist encounters: “My separation is failing at this stage”, “I can’t achieve sufficient purity with this method”, “My intermediate is precipitating unexpectedly.”.

These are indistinguishable from the questions a PhD student asks their supervisor every week. You cannot filter them without crippling legitimate research. And any actor far enough along to ask these engineering troubleshooting questions already possesses the domain knowledge to answer them independently – the practical bottlenecks in dangerous synthesis are often materials, equipment, and infrastructure, rather than information. Moreover, removing dangerous knowledge from a model creates its own risk: a model that no longer understands what makes a substance dangerous cannot recognise when it’s being guided through a dangerous synthesis. The request looks like organic chemistry homework – because to the model, it now is.
Current responses tend toward blanket knowledge restriction – training models to refuse broad categories of queries. This creates an asymmetric outcome: legitimate researchers lose access to AI assistance for routine scientific work, while determined actors turn to open-weight models, jailbreaks, or simply consult the textbooks that have been publicly available for decades. The restriction primarily inconveniences the people who least need restricting.
Information does matter – the question is whether you can distinguish who’s asking and why. One avenue is behavioural anomaly detection: monitoring patterns across sessions rather than filtering individual queries. Systematic probing of adjacent knowledge domains, drift in query topics over extended conversations, or coordinated knowledge extraction across multiple accounts could provide early warning of misuse attempts. But this approach runs directly into privacy concerns that Europe rightly takes seriously. The tension is real: effective detection of misuse patterns requires exactly the kind of user behaviour analysis that GDPR constrains. This is an area where careful research within ethical frameworks is needed – not deployment, but investigation of what’s even possible within European values.
Different knowledge domains carry fundamentally different risk profiles, and conflating them undermines both safety and utility. Nuclear proliferation is primarily bottlenecked by material acquisition and industrial infrastructure. Chemical threats present more distributed risks, as history has demonstrated. Biological threats occupy a middle ground where synthesis knowledge may provide more meaningful uplift. Each requires a distinct response – not a single blunt filter applied equally to organic chemistry homework and weapons design.
Build the Firewall, Not the Filter
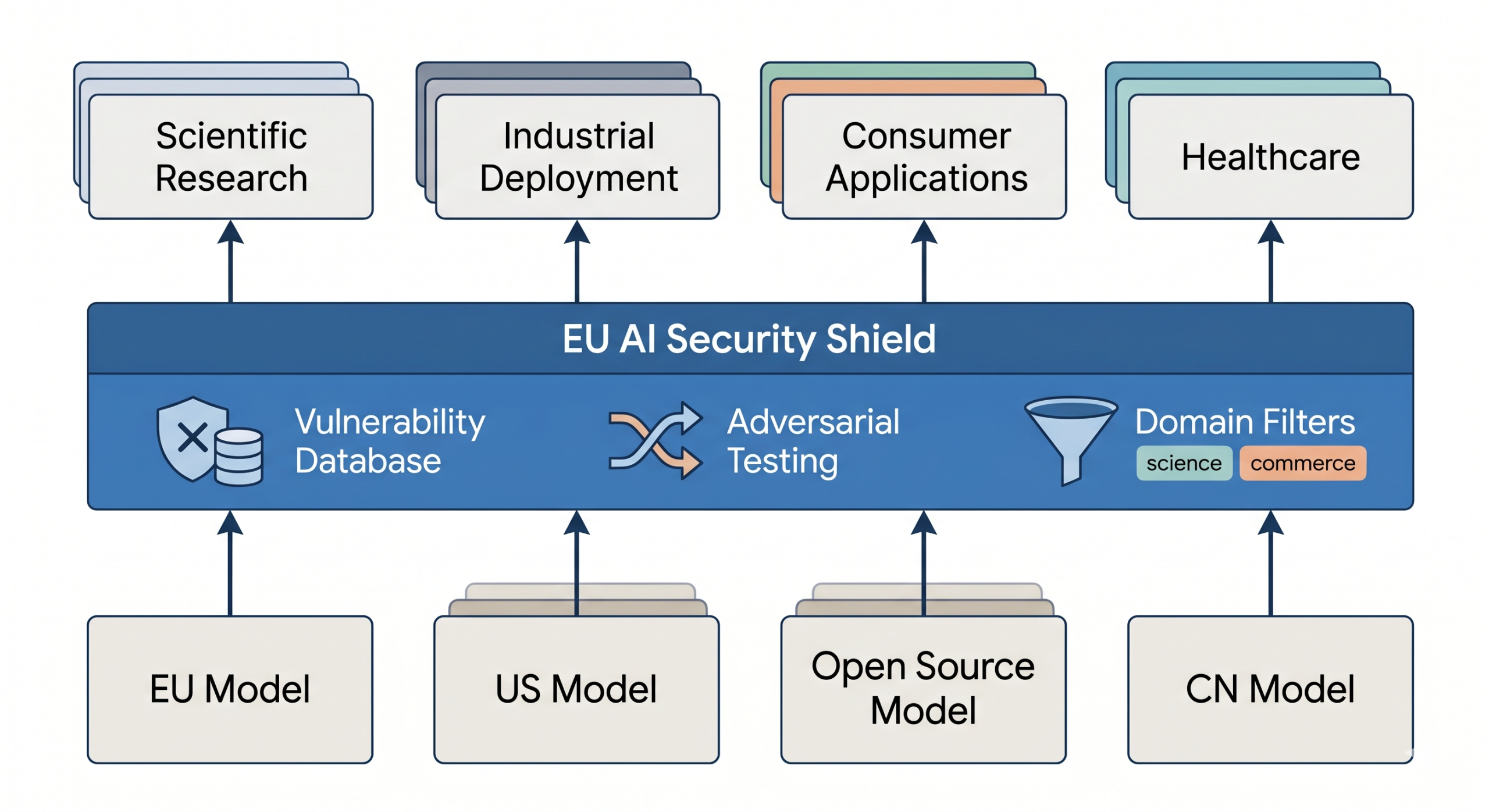
Rather than relying on each model developer to independently solve safety, we propose that the EU fund security as shared infrastructure – separable, modular, and maintained as a public good.
The architectural pattern already exists. Meta has released Llama Guard and Prompt Guard as open-source safety layers that sit in front of language models. NVIDIA’s Garak provides adversarial probing frameworks. But these are individual corporate contributions, maintained at the discretion of their creators and aligned with their priorities. What Europe needs is to take this pattern – security as a separable infrastructure layer – and fund it as continuously maintained public goods. Extend existing open-source safety models, retrain them for European languages and regulatory contexts, and adapt the architecture for domain-specific threats that commercial providers have little incentive to address.
Concretely, this means:
- An EU AI Security Commons — publicly funded security shield models that sit in front of any base model, regardless of origin. When a new vulnerability is discovered, the shield is updated once and every European deployment behind it is protected. European model, American model, Chinese model: same protection layer.
- Standardised adversarial testing frameworks — centralised probes incorporating domain expertise from chemistry, biology, nuclear security, and cybersecurity, enabling systematic vulnerability assessment beyond what any single organisation can achieve alone.
- Domain-calibrated security tiers — lightweight shields for consumer chatbots, more sophisticated protection for high-capability scientific systems, keeping overhead proportional to actual risk.
- A vulnerability reporting ecosystem — modelled on CVE practices in cybersecurity, with structured reporting channels for researchers, practitioners, and the public, enabling the security community to prioritise the most critical threats.
This protects European deployments regardless of where the underlying model originates — and regardless of whether that model’s developer complies with EU regulation. That matters, because determined misuse will always gravitate toward the least-regulated available system. The alternative is hoping that every model deployer in Europe independently implements adequate safety measures. That hope is not a strategy.
Sovereignty Through Capability, Not Isolation
Europe needs the capability to train frontier models. This is a matter of strategic optionality – if open-source model licences change, if export restrictions tighten, if geopolitical alignment shifts, Europe must have a credible alternative. The investments in AI Factories, EuroHPC, and domestic developers like Mistral serve this purpose and should continue.
But sovereignty doesn’t require rebuilding everything from scratch. It requires the ability to choose. Open-source frontier models – from Llama to Qwen to Mistral – provide a foundation that European companies and researchers can build upon today, without waiting for a European GPT to materialise. The sovereign capability is in knowing how to adapt, evaluate, secure, and deploy these models within European regulatory and ethical frameworks. That is itself a form of technological independence.
At the same time, Europe should actively shape the conditions under which international AI developers operate on European soil. General incentive frameworks – compute access for R&D, infrastructure partnerships, favourable conditions for providers delivering inference from European data centres – can reward any AI developer deepening their European presence and demonstrating commitment to responsible development. As geopolitical dynamics shift and some developers find their safety commitments increasingly at odds with the regulatory direction of other jurisdictions, Europe has an opportunity to position itself as the most attractive ecosystem for safety-conscious AI development globally. This isn’t about picking winners. It’s about making Europe the obvious choice for those who share our values.
What We’re Asking For
When we sit down at the Forum next week, these are the concrete proposals we’ll be pushing for:
- Fix the funding criteria. Recognise that efficient adaptation of frontier models delivers comparable industrial value to training new ones. Horizon Europe and Digital Europe evaluations should reflect this — with dedicated funding lines for post-training research.
- Create an SME compute credit programme. Targeted AI Factory allocations assessed by innovation potential, not training scale. Europe’s compute infrastructure should serve startups doing adaptation work, not just consortia running massive training jobs.
- Fund the AI Security Commons. Public security infrastructure that protects all European AI deployments — updated centrally, available to everyone, independent of any single model provider.
- A regulatory sandbox for scientific AI. Controlled environments where high-capability models can be deployed for legitimate research while maintaining appropriate safeguards, enabling Europe to lead in responsible high-capability AI for science.
- Build domain-specific benchmarks. Co-developed with scientific and industrial communities, built from real-world data, regularly refreshed, and linked to repositories like Zenodo.
- Shared research infrastructure. EU-funded repositories for domain-specific model adaptations and synthetic data quality standards, reducing duplication across projects and establishing fitness-for-purpose benchmarks.
- Connect AI to EOSC. The European Open Science Cloud has the data. AI systems need standardised protocols to access it. This integration is underdeveloped and systematically underestimated.
- Fund cross-disciplinary PhDs. Europe produces excellent physicists and excellent computer scientists. It rarely produces someone who is both. Marie Curie actions could fix this with dedicated dual-expertise doctoral tracks.
The European Expert Forum on Frontier AI meets for the first time on 23 April 2026, convened by the European Commission’s AI Office. ePotentia is a Belgian AI company developing novel AI systems for scientific and industrial domains, including through the Horizon Europe project AID4GREENEST and the open platform MicrostructureDB.com. All opinions expressed within this blog post are that of ePotentia alone.